Multiple imputation for multilevel data with continuous and binary variables
Abstract
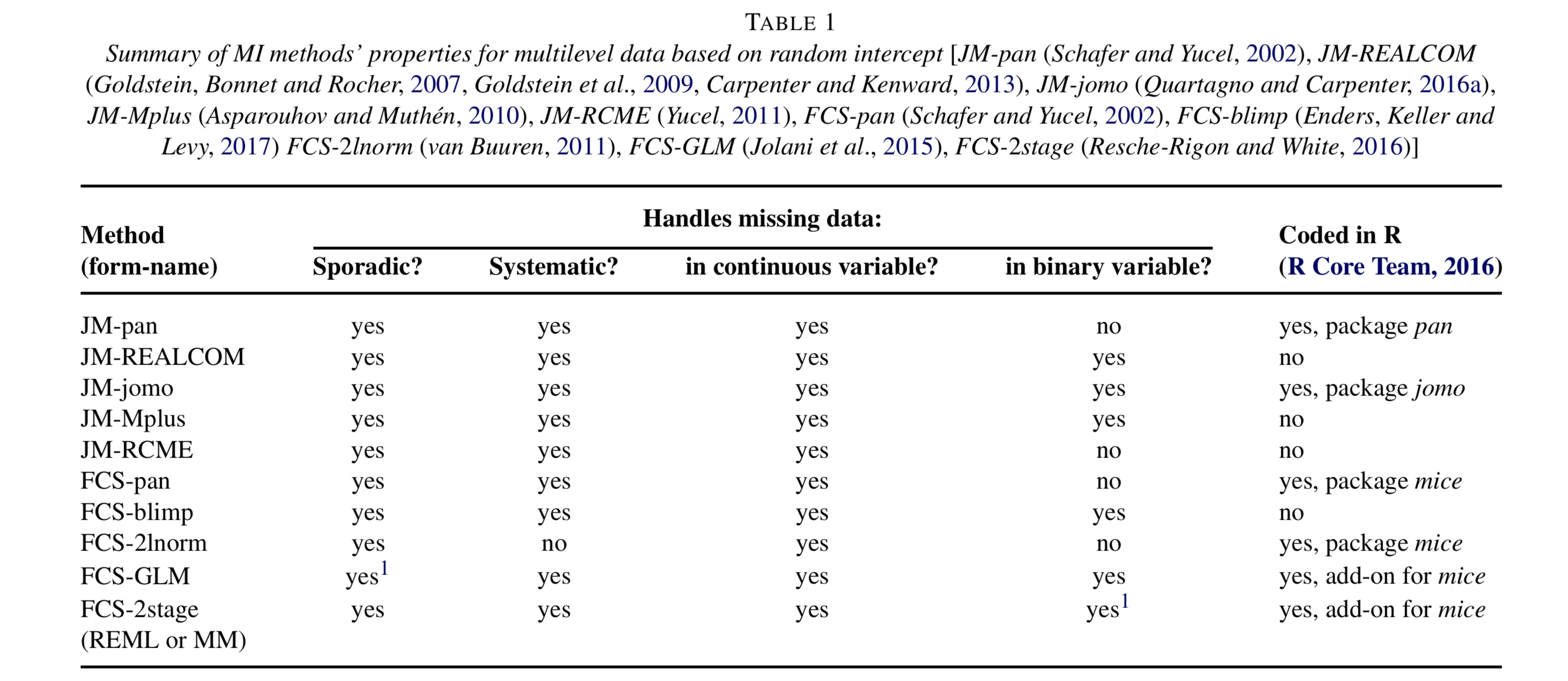
We present and compare multiple imputation methods for multilevel continuous and binary data where variables are systematically and sporadically missing. The methods are compared from a theoretical point of view and through an extensive simulation study motivated by a real dataset comprising multiple studies. The comparisons show that these multiple imputation methods are the most appropriate to handle missing values in a multilevel setting and why their relative performances can vary according to the missing data pattern, the multilevel structure and the type of missing variables. This study shows that valid inferences can only be obtained if the dataset includes a large number of clusters. In addition, it highlights that heteroscedastic multiple imputation methods provide more accurate inferences than homoscedastic methods, which should be reserved for data with few individuals per cluster. Finally, guidelines are given to choose the most suitable multiple imputation method according to the structure of the data.